Note: I gave this presentation at LITA Forum on November 7, 2014 as “What Does Your Repository Do? Measuring and Calculating Impact”. This is an on-going research project, which I will be expanding and revising for publication.
This research grew from various questions I have asked myself over the last nearly two years I have managed a repository. I began the work over the summer of 2014, and have much more data to analyze, but this is a beginning at developing a more nuanced understanding of the impact of institutional repositories (IR).
A Few Caveats
Photo taken by the author at the Seattle Public Library. Spot the misshelving error for librarian credits.
To “calculate” implies that math will be done, and I will be doing no math here. I will leave that for the bibliometrics research centers who work I will cite. Furthermore, finding a statistically significant result in the relatively small data sets most of us are considering would be difficult if not impossible.
Another meaning of calculate implies a thoughtful reckoning about one’s actions, though often with a connotation of nastiness or at least base pragmatism. (Women in Jane Austen novels are often forced to be calculating about their marriage prospects). We are all forced by pragmatic considerations to plan and justify our projects, and by extension our continued employment on those projects. So a little calculation–of the reckoning or the mathematical kind–is well advised.
It’s worth noting that I will talk about impact at both a personal and an organizational level, partly because the personal is political at so many academic institutions, and since we wouldn’t have these repositories at all if it weren’t for our people. That said, I won’t get into the details of metrics for personal impact much. They are an intensely debated subject, and I do not have room to give them justice here.
Lastly, I will describe how one might use data to create reports to help answer one set of questions. But there are many more questions that could be asked, and that will partly depend on your needs. I am speaking of repositories that are primarily open access full text databases of text or image, and usually ones based at a specific university. Many of these suggestions apply to any digital project, however.
Why a more nuanced understanding?
“Repository managers understandably focus on filling the repository at all costs, since the easiest (though undoubtedly the least useful) measure of repository success is growth in collections…and items…
This quote from the seminal “Innkeeper at the Roach Motel” by Dorothea Salo sums up some of the major struggles that repository managers have with determining success.. Numbers are easy to get, but they are just numbers. Large numbers of items and high download counts may satisfy administration, but they don’t tell a story about what value your repository adds to the world. I suggest that understanding the impact of your repository requires first understanding where on a continuum of success you want to be.
Who Are We Doing This for Anyway?
Photo by the author of one of her cats and her baby, for whom she is doing this.
For many of us, the open access piece is the reason we get out of bed in the morning. Providing access to people across the world or in our own country who might not have access to all the journals they need to do research is a worthwhile goal. Even those at large well-funded institutions can benefit, however. In doing the research for this presentation I came across many articles that my library doesn’t have–the university has no library science program, so there is no reason to subscribe to LIS journals. Even so, I only had to make one interlibrary loan request. All the other articles were available in post-print versions in institutional repositories, so I was able to get the text of the article. I am under no illusions about why that is–I am doing research about open access institutional repositories. I might not be so lucky in another area.
There are many more pragmatic and equally valid considerations for having an institutional repository beyond open access: highlighting the work of the faculty and students, preserving content, providing publishing platforms, and more we will discuss shortly. These are, in one sense, easier to measure, but still require some understanding of the continuum for success.
The Continuum of Success
Let’s look at the continuum. We have a range of reasons to have an IR, and range of ways to measure along those ranges.
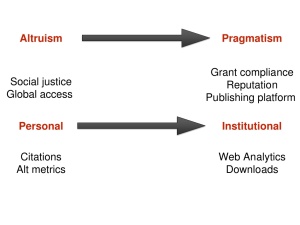
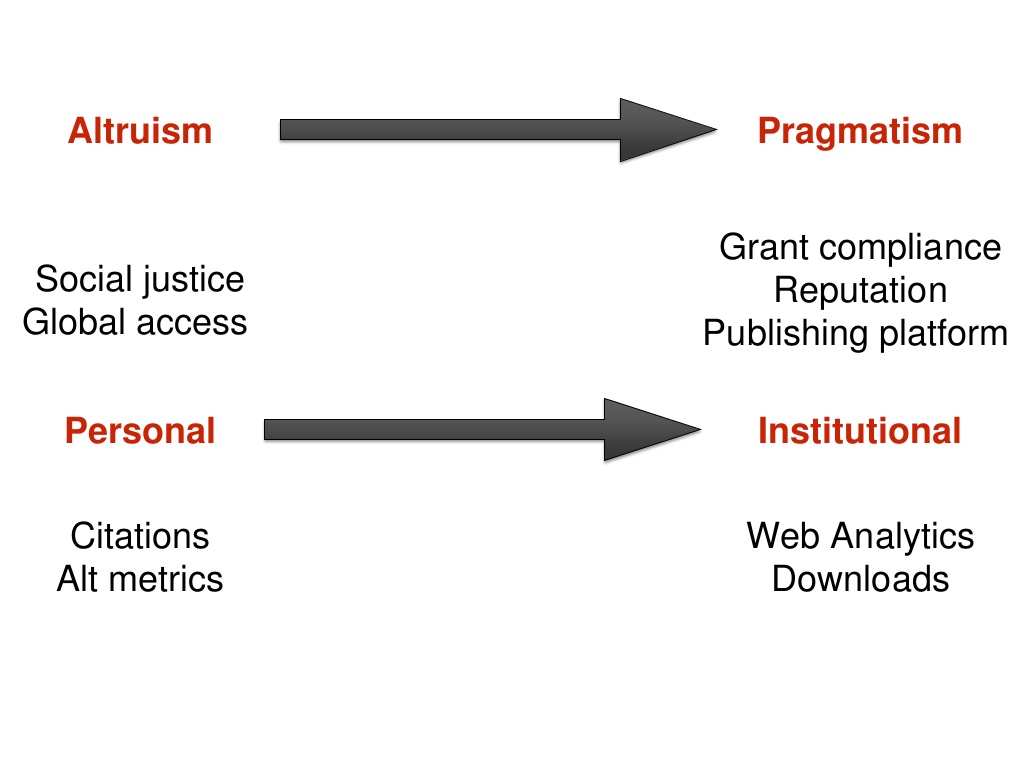
The altruistic considerations–which might include social justice and global reach as an effect of open access–may become progressively more pragmatic at both a personal and an institutional level, and of course one may have dual goals. For right now I am focusing on looking at the impact of open access IRs when it comes to global reach, institutional reputation, and a bit on citations. Ways of measuring that success might include for individuals citations (and traditional metrics) or alt metrics (which may include social media or other ways of understanding the impact of research.) At an institutional level, metrics found in web analytics or download counts may be more useful. Note that while I list alt metrics under individuals, they are increasingly being used as institutional metrics, particularly as well-established companies buy smaller companies (such as Elsevier’s acquisition of Mendeley). . At my own institution we take advantage of the Altmetric.com service built into Digital Commons for tracking articles, but many institutions are obtaining subscriptions to alt metric analytics services. Individuals may want to look into Impact Story, which is a member supported non-profit company with a nice set of services for building an online presence.
Let’s look at some specific examples of questions one might ask about success along this continuum and effective ways to measure that success.
Open Access and Citations
One of the purported pragmatic benefits to open access IRs is the higher citation rate. Many studies show that there is at least some advantage to open access in terms of citations, but it is very difficult to construct a study that measures this satisfactorily. In 2010 Alma Swan did a useful analysis of studies that broke down the disciplines and causes for the effect. The problem with all such studies is that it is challenging to control for factors such as journal prestige and researcher profile. A 2013 study by Mark McCabe and Christopher Snyder claimed to do just that, however, and found a rather modest 8% open access citation advantage, but found in some cases open access had a lower citation rate, which they suggested was due to more competition between available articles.
Web Usage and Citations
I wanted to see what the relationship between article usage and citations was in my own repository. To create this report, I looked how many times an item was downloaded according to Digital Commons counts (which try hard to eliminate bots that artificially inflate numbers), and checked for number of citations in Google Scholar and readers in Mendeley. Items in italics indicate items I suspect were cited due to inclusion in eCommons, bolded are items I can prove were cited due to inclusion in eCommons.
| Article |
eCommons Downloads |
Google Scholar Citations |
Mendeley |
| Jane P. Currie, (2010) “Web 2.0 for reference services staff training and communication”, Reference Services Review, Vol. 38 Iss: 1, pp.152 – 157 |
27340 |
10 |
30 |
| Milton’s Use of the Epic Simile in Paradise Lost (1941 thesis) |
8517 |
0 [1 in Google] |
0 |
| Expressionism in the Plays of Eugene O’Neill (1948 thesis) |
6854 |
2 |
0 |
| Comics and Conflict: War and Patriotically Themed Comics in American Cultural History From World War II Through the Iraq War (2012 thesis) [self-citation] |
6650 |
1 |
0 |
| The Refractive Indices of Ethyl Alcohol and Water Mixtures (1939 thesis) |
5995 |
1 |
0 |
| Population Dynamics and the Characteristics of Inmates in the Cook County Jail (research report) |
5602 |
2 |
0 |
| Home Networking |
5509 |
4 |
8 |
| Education, Fascism, and the Catholic Church in Franco’s Spain (2012 thesis) |
5070 |
0 |
0 |
| An Analysis of Language, Grammatical, Punctuation, and Letter-Form Errors of Fourth-Grade Children’s Life Letters (1938 thesis) |
4706 |
1 |
0 |
| The Influence of Certain Study Habits on Students Success in Some College Subjects (1932 thesis) |
4200 |
0 |
0 |
Can you spot what the bold items have in common? They are all unpublished. Most are theses or dissertations, and one is a research report posted in the repository to meet a grant requirement. It is very challenging to determine what is cited because it was in a repository, and you can really only be sure when the the repository URL is included. Of course you wouldn’t want it any other way–you want articles to be cited in their published form, even if the IR was the mode of discovery. I suspect that the item in italics was cited due to inclusion in the repository because of where and when it was cited after 2012 when it was first posted. Either way, the repository has given an amazing continued life to a 2010 article that might otherwise not have been read so frequently. Many of the open access citation studies determined that early access to articles improves citations, but generally that occurs in subject repositories rather than institutional repositories. It is probable that inclusion in institutional repositories helps longer term or wider citation over time. The two citations of the 1948 thesis about Eugene O’Neill very much illustrate that point. I was curious about those citations in particular, because they both came from Iranian scholars of English literature.
The Iranian Citations
Because I was curious, I wrote to these two researchers and asked them the following questions:
“How did you discover this thesis?” “What made you choose to cite it in your article?” and “How did this source compare to other sources you cited?”
“…due to the limited range of books on O’Neill within my reach I had to resort to such texts to fill the gap.” (Researcher 1)
“…the good citation of footnotes which are doors to other useful works for my article…” (Researcher 2)
They both found the article by searching Google. They both mentioned that it covered the specific topic better than anything else, was well-organized, and contained a number of citations and quotes that were useful. Neither of them mentioned the age of the piece.
The plight of the English literature scholar in Iran is illustrative of the promise and danger in making student theses available open access. A 2014 study of citations of open access undergraduate theses across 49 repositories found that 4% of undergraduate theses were cited a total of 1,390 times. The authors concluded that much of the reason for citations are papers that are on cutting edge or local interest topics for which not much else is available. In some cases the theses were of poor quality, which is a common worry in providing access to student work.
Nevertheless, improving global access is a major goal of open access IRs, and measuring and illustrating that is crucial to understanding impact.
A Brief Tangent into Methods
In the following sections I’m going to use web analytics to answer a few questions about global reach and traffic sources. So here’s how I created those reports. I looked at data from Loyola earlier this year, but I wanted to see if the conclusions I had from that set were the same at other institutions. I have a lot of data by now, and this will be an ongoing project to analyze it, but for today I’m just showing data from 4 institutions, all of whom use Digital Commons by bepress for their institutional repositories.
| SUNY Brockport |
Undergrad: 7,090
Grad: 1,038 |
3,884 items
601,516 downloads |
| University of Montana |
Undergrad: 12,657
Grad: 2,289 |
9,780 items
195,159 downloads |
| Loyola University Chicago |
Undergrad: 9,240
Grad: 5,524 |
4,389 items
756,820 downloads |
| Marquette University |
Undergrad: 8,365
Grad: 3,417 |
10,772 items
1,624,195 downloads |
They are all a similar size, but only Marquette is particularly similar to Loyola. I asked for exports from Google Analytics of all traffic between October 1, 2013 and October 1, 2014 of three separate reports: location, traffic, and organic (i.e. not paid) keywords. For location I wanted to find out which countries were the heaviest users of the repositories, and which seemed to have the most engaged users, and see what was unique or the same. That was just a matter of sorting in Excel.
For Traffic and Keywords I used a slightly more complicated approach. I used OpenRefine to cluster and categorize data, and then used pivot tables in Exel to rank traffic sources and keywords. ‘Clustering” means I used algorithms in OpenRefine to find things that were probably the same concept: e.g. censorship united states = “united states” + censorship. Those are fairly rough numbers, but the program makes this much faster when you are trying to categorize thousands of records.
Global Access to Research
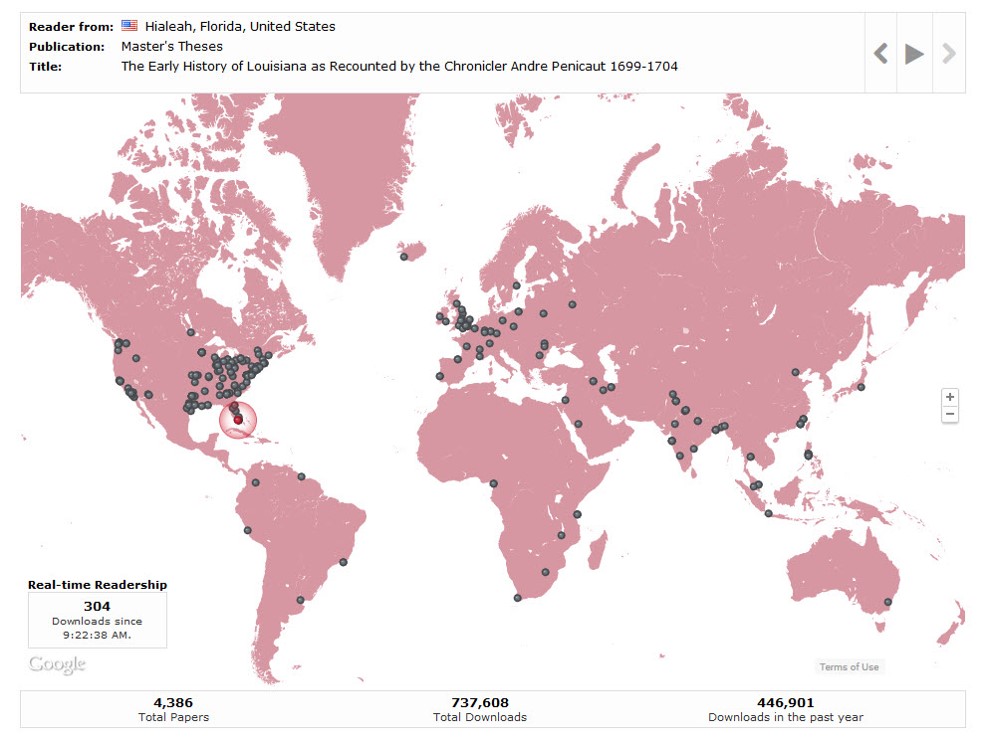
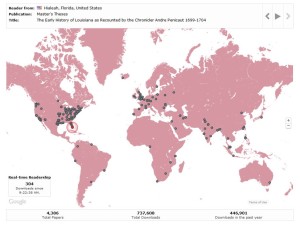 This map is a recently added feature of the Digital Commons platform, which provides real time data of downloads of materials worldwide. This is an example of the map after I’d left it running all day on an average day in the middle of the semester. After about 7 hours we had downloads from all continents (I’ve even seen Greenland some days, but today we had Iceland). This is a wonderful promotional tool to have (sidebar: this was much discussed on the backchannel and in hallway discussions after the talk). We displayed it at our recent Celebration of Faculty Scholarship and had a group gathered around watching and talking about it.
This map is a recently added feature of the Digital Commons platform, which provides real time data of downloads of materials worldwide. This is an example of the map after I’d left it running all day on an average day in the middle of the semester. After about 7 hours we had downloads from all continents (I’ve even seen Greenland some days, but today we had Iceland). This is a wonderful promotional tool to have (sidebar: this was much discussed on the backchannel and in hallway discussions after the talk). We displayed it at our recent Celebration of Faculty Scholarship and had a group gathered around watching and talking about it.
The usefulness is that is shows how global reach is happening, which can otherwise be hard to articulate, but is truly a crucial effect of IRs. A 2012 study of 140 lecturers at a university in Nigeria found that 81% of them regularly accessed open access journals, and 91% cited open access articles. Important constraints to usage were problems such as power outages, unavailability of internet, and limited access to computers. 82% felt that increasing internet availability and 77% felt that establishing institutional repositories would improve the situation for open access. Another research team looked at citations of open access articles by African researchers in corrosion chemistry. They found that African researchers were twice as likely to cite open access articles as those in non-African countries.
I wanted to look at how global effect worked in several ways. First, I looked at which countries had the highest number of sessions for a given repository. Here’s a chart of that, and note that the bolded country is unique to that institution:
| Loyola |
SUNY Brockport |
Montana |
Marquette |
| United States |
United States |
United States |
United States |
| United Kingdom |
United Kingdom |
Canada |
United Kingdom |
| Canada |
Canada |
United Kingdom |
Canada |
| India |
Australia |
India |
India |
| Australia |
India |
Germany |
China |
| Germany |
Philippines |
Australia |
Australia |
| Philippines |
Germany |
China |
Germany |
| China |
China |
Japan |
Italy |
| Italy |
Brazil |
Philippines |
South Korea |
| Spain |
Malaysia |
Brazil |
Philippines |
Not surprisingly, the Us, the UK, and Canada came out on top across all four. I note that Spain is unique to Loyola, and I know we have quite a few items in Spanish and about Spain, so I suspect that may be the reason. I am also pleased to note Italy is in the top 10, since we have quite a few items about Italian history.
While sheer numbers are interesting, they do not tell the whole story. I wanted a way to measure the most engaged users, whether or not they had the most sessions. After some trial and error, I settled on measuring the most pages per session. I originally looked at longest session times, but it was pointed out to me that these were most likely places with slow internet connections. Here is the list of the top 10 countries by session. Pay close attention to the bolded country in each column.
| Loyola |
SUNY Brockport |
Montana |
Marquette |
| Sierra Leone |
Oman |
Gambia |
Timor-Leste |
| Ukraine |
Dominica |
Mauritius |
Mozambique |
| Iraq |
Guatemala |
United States |
Gambia |
| Nicaragua |
Mauritius |
Sudan |
Madagascar |
| Mauritius |
U.S. Virgin Islands |
Saudi Arabia |
Bermuda |
| Ecuador |
United States |
Malawi |
Armenia |
| Myanmar (Burma) |
St. Vincent & Grenadines |
Kyrgyzstan |
Mauritius |
| Dominican Republic |
Belarus |
Peru |
Zambia |
| Belarus |
Rwanda |
Algeria |
Tonga |
| Jersey |
Sweden |
Japan |
Laos |
Careful observers will note that Mauritius was in the top ten across all four institutions. This immediately struck me, since I did not know much about Mauritius and wanted to know why it kept appearing. Mauritius, while isolated geographically, has made a push over the last 15-20 years to increase the information technology sector . A recent in depth case study of the University of Mauritius shows the tensions of doing research at a university (like many in the United States) which has shifted its strategic goals towards being an internationally known research center without necessarily having the entire infrastructure to support those goals. Scholars have access to Science Direct through the government, but usage has not been as high as hoped. This study reports that many scholars at the University of Mauritius “UoM FoS scholars say that they use academic databases most often (74%) for finding econtent. This is followed by searching through aggregated journals (47%), Google Scholar (43%) and pre-print repositories (40%). This is a common pattern of usage in institutions that do not subscribe to large numbers of journals, but rely on package subscriptions with a few big publishing firms.” Scholars cannot rely on being able to download items from Google Scholar which is why they don’t always use it. Interestingly, most scholars rely on international research partners or colleagues for access to materials, though some find having to ask for articles embarrassing and that they don’t want to be perceived as “beggars” for funding or research materials.
I find this a tremendously strong argument for making research available open access. The fact is that Mauritius has a good ICT infrastructure compared to many countries, and has big goals for the future to be a global knowledge disseminator. By making work open access we allow scholars there to participate in global knowledge creation at some level of equality and dignity, and we will all benefit from this.
Traffic Sources
How are people are finding their ways to repositories? How does traffic get referred, either by other websites or search engines? And what keywords are people using? Understanding this is I think part of explaining to an institution why having a repository matters for institutional mission and reputation. I suspected before I did this research that keywords and traffic sources would somewhat align with those things—that if the institution had representation of its strengths in the repository that would be reflected in how people were finding it. There are some problems with these numbers—first I couldn’t analyze all of the trends properly, so these are definitely leaving out some things. Yearbooks, in particular, I think were more common searches than show up here.
| Loyola |
SUNY Brockport |
Montana |
Marquette |
| google |
google |
google |
google |
| Facebook |
brockport.edu |
umt.edu |
marquette.edu |
| luc.edu |
leiterreports.typepad.com |
lib.umt.edu |
bing |
| scholar.google.com |
network.bepress.com |
digitalcommons.bepress.com |
business.marquette.edu |
| libraries.luc.edu |
digitalcommons.bepress.com |
kpax.com |
yahoo |
| network.bepress.com |
bing |
works.bepress.com |
scholar.google.com |
| bing |
digitalcommons.brockport.edu/pes_facpub/21 / PDF |
umt.summon.serialssolutions.com |
works.bepress.com |
| oatd.org |
yahoo |
life.umt.edu |
network.bepress.com |
| digitalcommons.bepress.com |
scholar.google.com |
network.bepress.com |
libus.csd.mu.edu |
| yahoo |
Twitter |
bing |
baidu |
Across all repositories, the highest driver of traffic was Google, and the Digital Commons Network, which has material from all institutions is also an important driver of traffic. Note that social media is also a big player, though how much varies.
This next chart is an attempt to categorize drivers of traffice, which are presented here in order by number of sessions. These are inexact, but show that search engines, institutional websites, and academic websites are all driving traffic.
| Loyola |
SUNY Brockport |
Montana |
Marquette |
| Search Engine |
Digital Commons Repository |
Search Engine |
Other Website |
| Loyola Site |
Google Scholar |
University of Montana Website |
Search Engine |
| Google Scholar |
Academic Website |
Digital Commons Repository |
Marquette Website |
| Digital Commons Repository |
Brockport Website |
Academic Search Engine |
Digital Commons Repository |
| Facebook |
Facebook |
News Media |
Google Scholar |
| Academic Search Engine |
Other Website |
Google Scholar |
Academic Search Engine |
| Twitter |
Academic Search Engine |
Academic Website |
Academic Website |
| Faculty Website |
Search Engine |
Email |
Baidu |
| Blog |
Twitter |
Other Website |
News Media |
| Other Website |
Blog |
Facebook |
Facebook |
| Email |
Mail |
Twitter |
Blog |
| RSS |
Reddit |
Google Translate |
Wikipedia |
| Baidu |
LinkedIn |
Digital Commons Repository |
Metafilter |
| Unknown |
RSS |
Blog |
Link Resolver |
| Academic Website |
Unknown |
Unknown |
Google Translate |
| Google Translate |
Weibo |
Amazon |
Unknown |
| Academic Library |
Google Translate |
Baidu |
Email |
| Link Resolver |
Wikipedia |
RSS |
Twitter |
| LinkedIn |
Baidu |
LinkedIn |
LinkedIn |
| Wikipedia |
Tumblr |
|
RSS |
| Reddit |
Digital Commons Repository |
Faculty Website |
| Government Webiste |
Faculty Website |
|
Academic Search Engne |
|
Link Resolver |
|
Amazon |
|
Email |
|
|
I last looked at keyword groupings, which as you may recall I created using clustering in OpenRefine.
| Loyola |
SUNY Brockport |
Montana |
Marquette |
| ecommons |
“sports psychology” |
scholarworks umt |
ethical marketing |
| “asexuality” |
“netflix” |
http://scholarworks.umt.edu/umcur/2014/oralpres2b/7/ |
feminism in frankenstein |
| literature postmodernism |
dialectical behavioral therapy |
amyotrophic lateral sclerosis |
frankenstein and feminism |
| year book |
ideal gas law |
short wave diathermy |
bitcoin |
| faq |
sex violence and media |
sustainability reporting |
censorship in the “united states” |
| email set up |
overrepresentation of minorities in special education |
mobile technologies |
ethics marketing |
| women advertisements france |
acceptance and commitment therapy |
calamity jane |
censorship, media, united states |
| year books |
gender in sports |
2014 university of montana graduate student research conference |
family communication |
| in literature postmodernism |
homophobia in sport |
evolution of avian flight |
conversations magazine |
| “virginia woolf” |
gender and sports |
recreation opportunity spectrum |
corporate censorship |
Interestingly enough, the two Jesuit universities—Loyola and Marquette—both have searches related to women and feminism in the top 10 keyword categories, as well as other topics that relate to social justice, which is a strong focus at Jesuit institutions. Brockport, which according to its website “has a long and rich history of producing some of the best sport and physical activity professionals in the country”, and indeed quite a few results appear to do with that. Montana has searches related to science and Calamity Jane, a historically important Montanan. So at this high level view, there is some relationship between strengths and searches. That said, what is missing from these lists is even more interesting. Looking at what people are finding and using I don’t see anything about environmental sustainability, which is a huge new research focus at Loyola. Why? We haven’t yet been able to add much of anything from that program to the repository, though are working on it. The few articles we have added are fairly recent in the past few months, and so don’t show up as huge keywords. I am sure repository managers at other institutions could tell a similar story.
In Conclusion
This is a first stab at answering several questions to measure the impact of an institutional repository between altruistic and pragmatic considerations, and at both a personal and institutional level. Much more remains to be done, but as a beginning stage I have several new stories to illustrate the value that my IR adds to the world.
I want to thank Rose Fortier from Marquette, Kim Myers from SUNY Brockport, and Wendy Walker from University of Montana for providing the data I used for this initial analysis. Many more colleagues from the Digital Commons mailing list provided data, and I will eventually finish analyzing all of it.